阿里云大数据利器之-RDS迁移到Maxcompute实现动态分区
摘要: 当前,很多用户的业务数据存放在传统关系型数据库上,例如阿里云的RDS,做业务读写操作。当数据量非常大的时候,此时传系关系型数据库会显得有些吃力,那么会经常有将mysql数据库的数据迁移到[大数据处理平台-大数据计算服务(Maxcompute,原ODPS)(https://www.aliyun.com/product/odps?spm=5176.doc27800.765261.309.dcjpg2),利用其强大的存储和计算能力进行各种查询计算,结果再回流到RDS。
点此查看原文:http://click.aliyun.com/m/40816/
当前,很多用户的业务数据存放在传统关系型数据库上,例如阿里云的RDS,做业务读写操作。当数据量非常大的时候,此时传统关系型数据库会显得有些吃力,那么会经常有将mysql数据库的数据迁移到[大数据处理平台-大数据计算服务(Maxcompute,原ODPS)(https://www.aliyun.com/product/odps?spm=5176.doc27800.765261.309.dcjpg2),利用其强大的存储和计算能力进行各种查询计算,结果再回流到RDS。
一般情况下,业务数据是按日期来区分的,有的静态数据可能是按照区域或者地域来区分,在Maxcompute中数据可以按照分区来存放,可以简单理解为一份数据放在不同的子目录下,子目录的名称以日期来命名。那么在RDS数据迁移到Maxcompute上的过程中,很多用户希望可以自动的创建分区,动态的将RDS中的数据,比如按日期区分的数据存放到Maxcompute中,这个流程自动化创建。同步的工具是使用Maxcompute的配套产品-大数据开发套件。下面就举例说明RDS-Maxcompute自动分区几种方法的使用。
一,将RDS中的数据定时每天同步到Maxcompute中,自动创建按天日期的分区。
这里就要用到大数据开发套件-数据集成的功能,我们采用界面化的配置。
如图地方,设置Maxcompute的分区格式
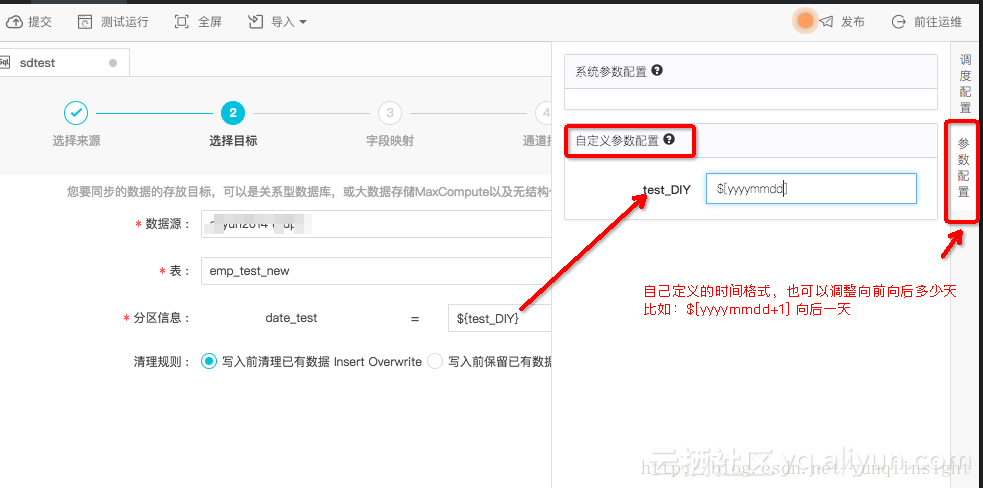
一般配置到这个地方的时候,默认是系统自带时间参数:${bdp.system.bizdate} 格式是yyyymmdd。也就是说在调度执行这个任务的时候,这个分区会被自动替换为
任务执行日期的前一天,
相对用户比较方便的,因为一般用户业务数据是当前跑前一天的业务数据,这个日期也叫业务日期。
如图
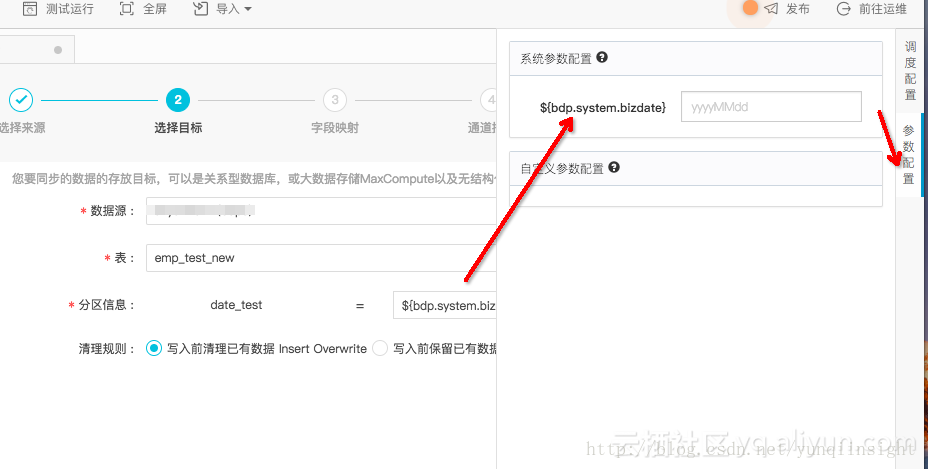
如果用户想使用当天任务运行的日期作为分区值,需要自定义这个参数,方法如图,也可以参考文档
https://help.aliyun.com/document_detail/30281.html?spm=5176.product30254.6.604.SDunjF
自定义的参数,格式非常灵活,日期是当天日期,用户可以自由选择哪一天,以及格式。
可供参考的变量参数配置方式如下:
后N年:[addmonths(yyyymmdd,12∗N)]前N年:[add_months(yyyymmdd,-12*N)]
后N月:[addmonths(yyyymmdd,N)]前N月:[add_months(yyyymmdd,-N)]
后N周:[yyyymmdd+7∗N]前N周:[yyyymmdd-7*N]
后N天:[yyyymmdd+N]前N天:[yyyymmdd-N]
后N小时:[hh24miss+N/24]前N小时:[hh24miss-N/24]
后N分钟:[hh24miss+N/24/60]前N分钟:[hh24miss-N/24/60]
注意:
请以中括号 [] 编辑自定义变量参数的取值计算公式,例如 key1=[yyyy−mm−dd]。默认情况下,自定义变量参数的计算单位为天。例如[hh24miss-N/24/60] 表示 (yyyymmddhh24miss-(N/24/60 * 1天)) 的计算结果,然后按 hh24miss 的格式取时分秒。
使用 add_months 的计算单位为月。例如 $[add_months(yyyymmdd,12 N)-M/24/60] 表示 (yyyymmddhh24miss-(12 N 1月))-(M/24/60 1天) 的结果,然后按 yyyymmdd 的格式取年月日。
如图,配置完成后,我们来测试运行看下,直接查看日志
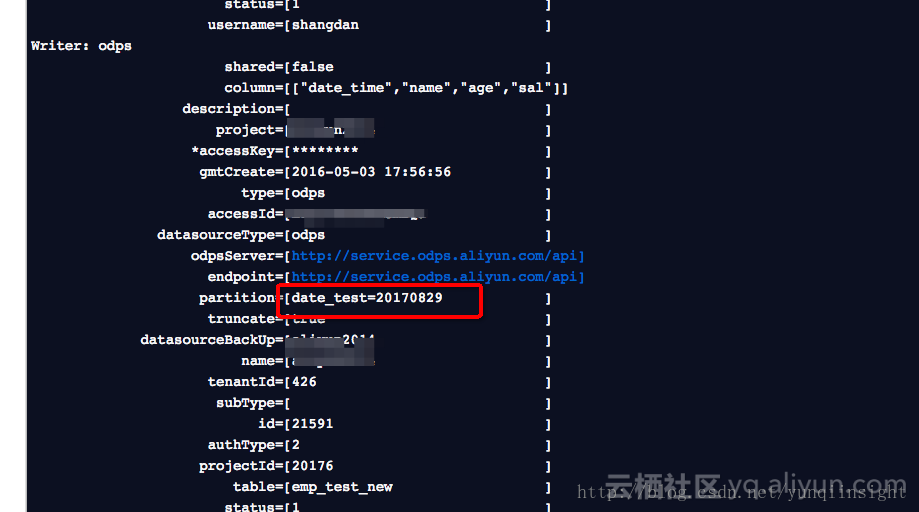
可以,看到日志中,Maxcompute(日志中打印原名ODPS)的信息中
partition分区,date_test=20170829,自动替换成功。
再看下实际的数据过去了没呢
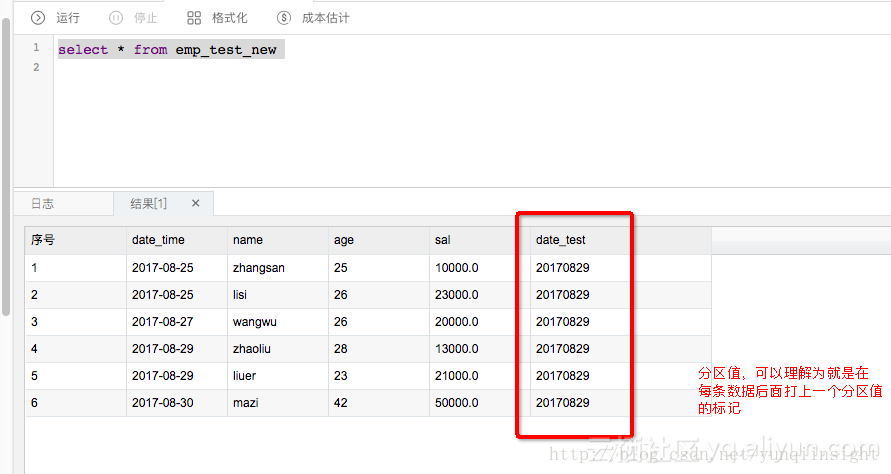
我们看到数据是过来了,成功自动创建了一个分区值。那么这个任务定时调度的时候,就会自动生成一个分区,每天自动的将RDS中的数据同步到Maxcompute中的按照日期创建的分区中。
二,如果用户的数据有很多运行日期之前的历史数据,怎么自动同步,自动分区呢。大数据开发套件-运维中心-有个补数据的功能。
首先,我们需要在RDS端把历史数据按照日期筛选出来,比如历史数据2017-08-25这天的数据,我要让他自动同步到Maxcompute的20170825的分区中。
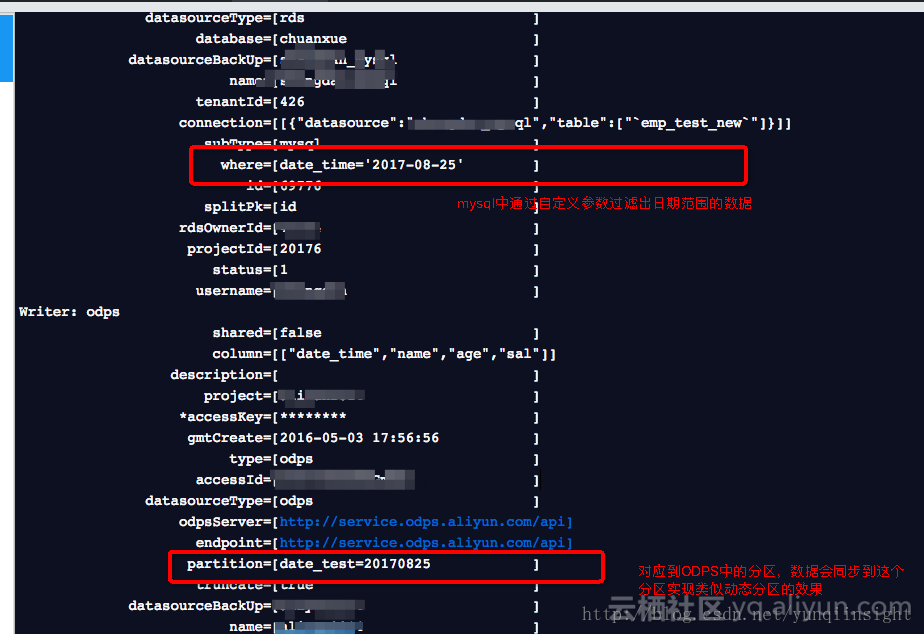
在RDS阶段可以设置where过滤条件,如图
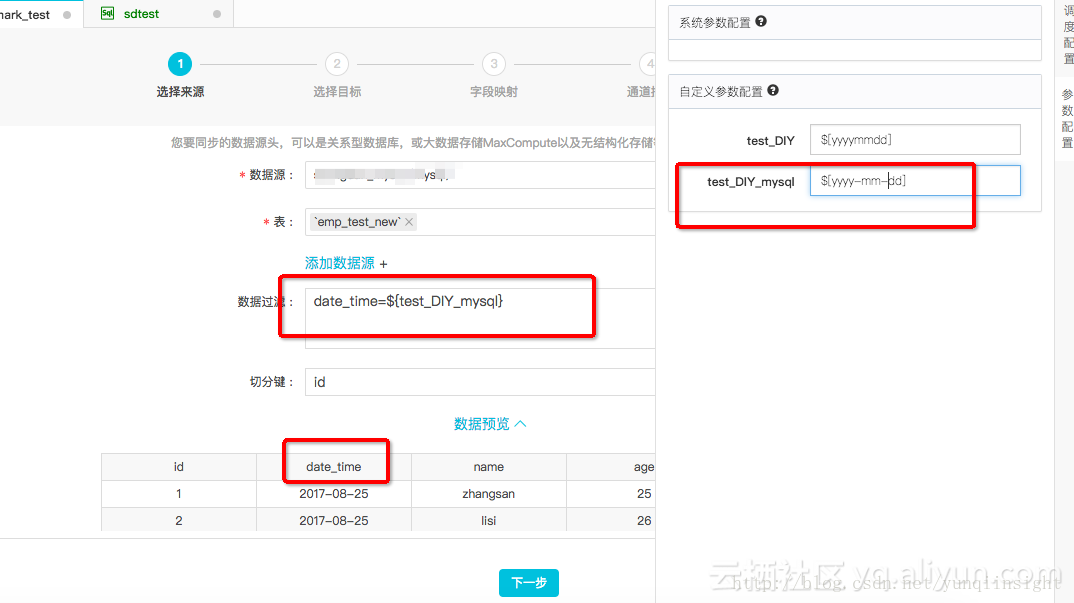
在Maxcompute页面,还是按照之前一样配置
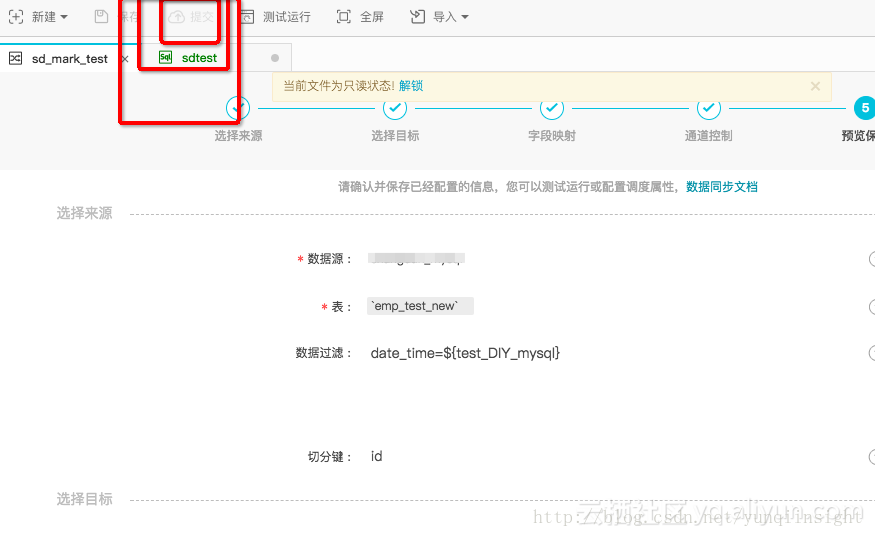
然后一定要 保存-提交。
提交后到运维中心-任务管理-图形模式-补数据
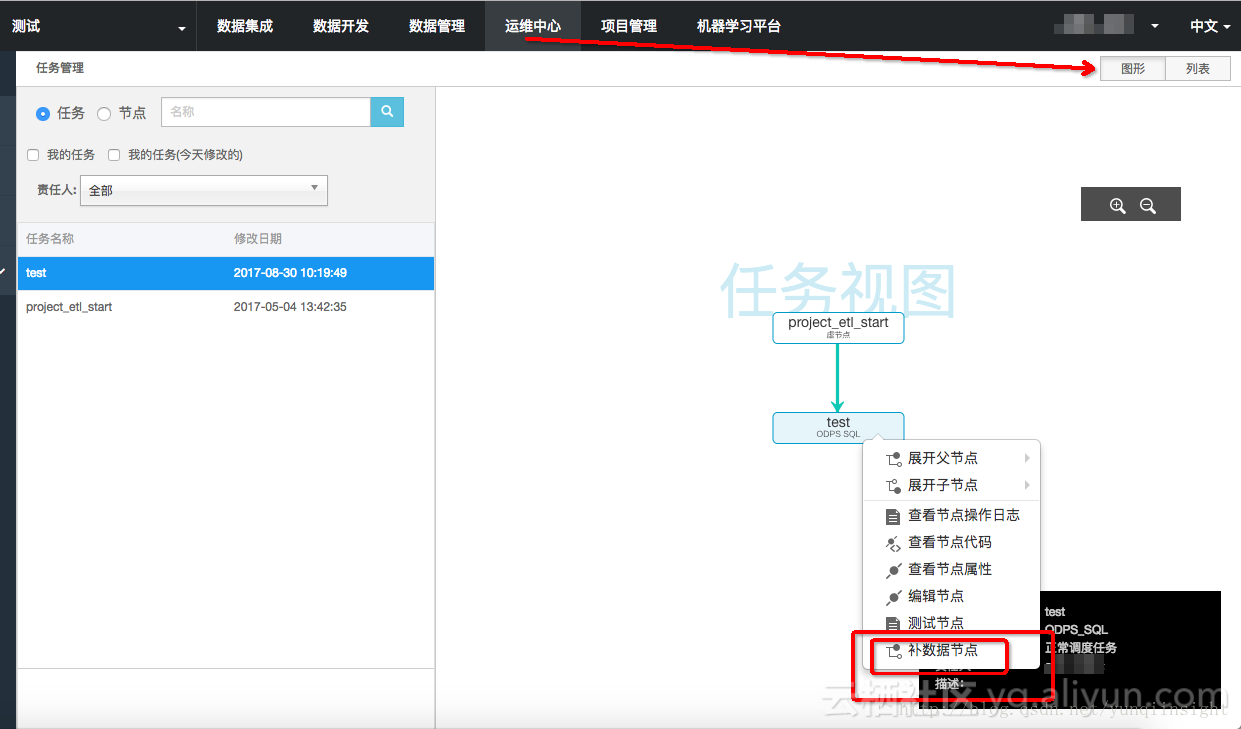
选择日期区间
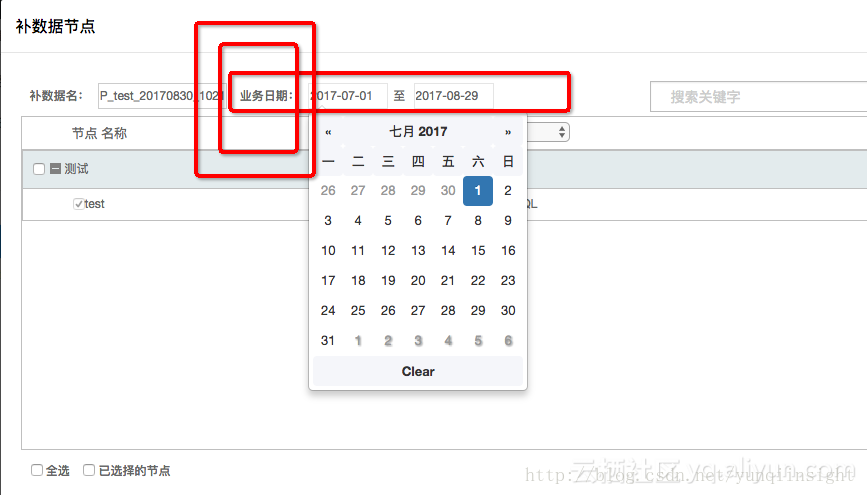
提交运行,这个时候就会同时生成多个同步的任务实例按顺序执行
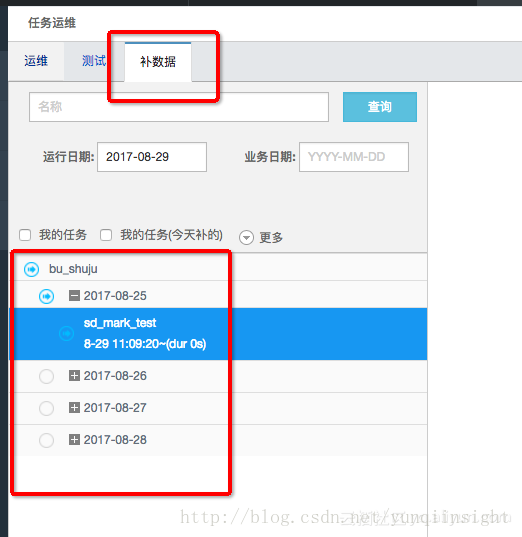
看下运行的日志,可以看到运行过程对RDS数据的抽取,在Maxcompute自动创建的分区
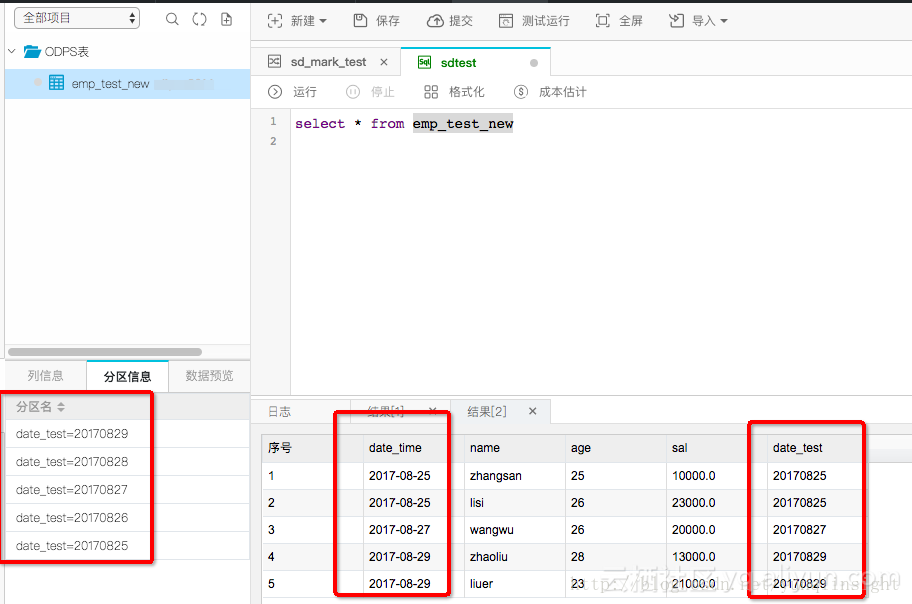
看下运行结果,数据写入的情况,自动创建了分区,数据同步过来了。
三,如果用户数据量比较巨大,第一次全量的数据,或者并不是按照日期分区,是按照省份等分区。那么此时数据集成就不能做到自动分区了。也就是说,想按照RDS中某个字段进行hash,相同的字段值自动放到Maxcompute中以这个字段对应值的分区中。
同步本身是做不了的,是在Maxcompute中通过SQL完成,是Maxcompute的特有功能,实际上也是真正的动态分区,大家可以参考文章
https://yq.aliyun.com/articles/81775?spm=5176.8091938.0.0.JMsroJ
。那么就需要我们先把数据全量同步到Maxcompute的一个临时表。
流程如下
1,先创建一个SQL脚本节点-用来创建临时表
droptableifexistsemp_test_new_temp;CREATETABLEemp_test_new_temp (date_time STRING, name STRING, age BIGINT, sal DOUBLE);
2,创建同步任务的节点,就是简单的同步任务,将RDS数据全量同步到Maxcompute,不需要设置分区。
3,使用sql进行动态分区到目的表
droptableifexistsemp_test_new;--创建一个ODPS分区表(最终目的表)CREATETABLEemp_test_new ( date_time STRING, name STRING, age BIGINT, sal DOUBLE) PARTITIONED BY( date_test STRING );--执行动态分区sql,按照临时表的字段date_time自动分区,date_time字段中相同的数据值,会按照这个数据值自动创建一个分区值--例如date_time中有些数据是2017-08-25,会自动在ODPS分区表中创建一个分区,date=2017-08-25--动态分区sql如下--可以注意到sql中select的字段多写了一个date_time,就是指定按照这个字段自动创建分区insertoverwrite tableemp_test_new partition(date_test)selectdate_time,name,age,sal,date_time fromemp_test_new_temp --导入完成后,可以把临时表删除,节约存储成本 droptableifexistsemp_test_new_temp;
最后将三个节点配置成一个工作流,按顺序执行
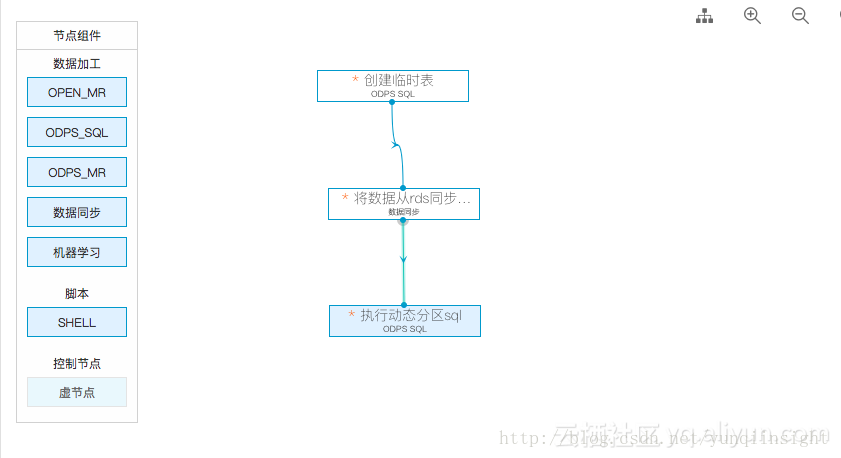
执行过程,我们重点观察,最后一个节点的动态分区过程
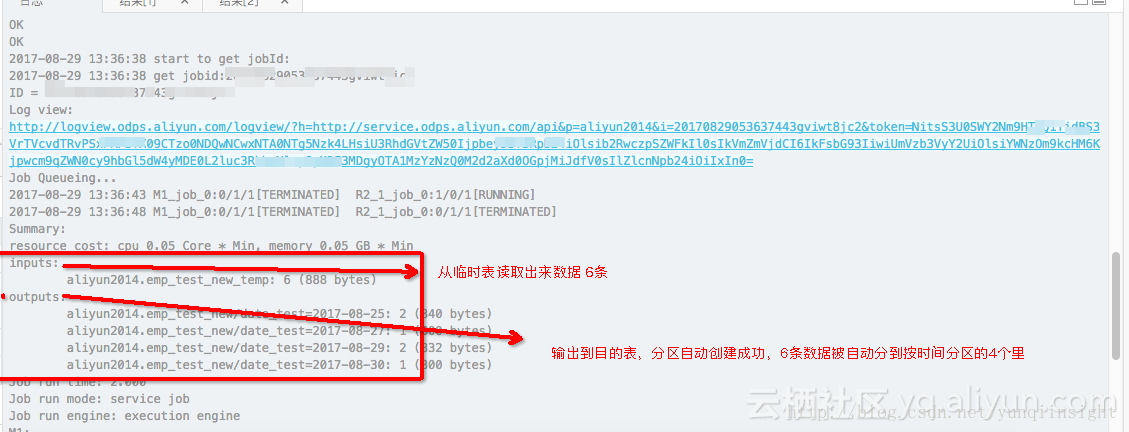
最后,看下数据
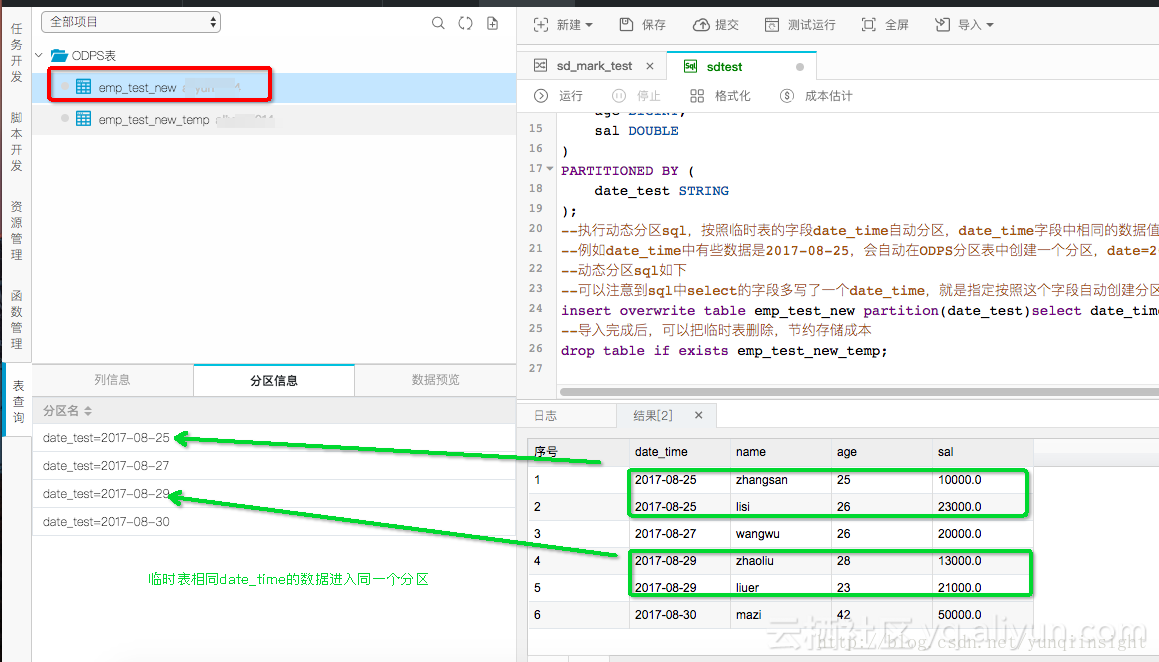
完成动态分区,自动化分区。是不是很神奇,相同的日期数据,到了同一个分区里。如果是以省份命名,也是如此,我自己都怕了。
大数据开发套件实际上可以完成绝大部分的自动化作业,尤其是数据同步迁移,调度等,界面化操作使得数据集成变得简单,不用苦逼的加班搞ETL了,你懂的。